Microservice Discord Bots
Read Time:5 minutes
In recent years, the Discord platform has been exploding in popularity - attracting thousands of different of communities from around the world. This has been made even more special by the platform's outstanding API, which allows for easy integration and creation of 3rd party apps, 'bots'. This has given rise to thousands of apps, each offering different functionalities and features, and many using traditional libraries such as discord.js and discord.py
However, these historically popular libraries are hugely limited when it comes to scalability, and accessing data from outside of the application - for example for use in a dashboard. After reading Das Wolke's White Paper on Microservice Bots, I was drawn to investigate the possible implementations of a scalable, and efficient package to work with Discord.
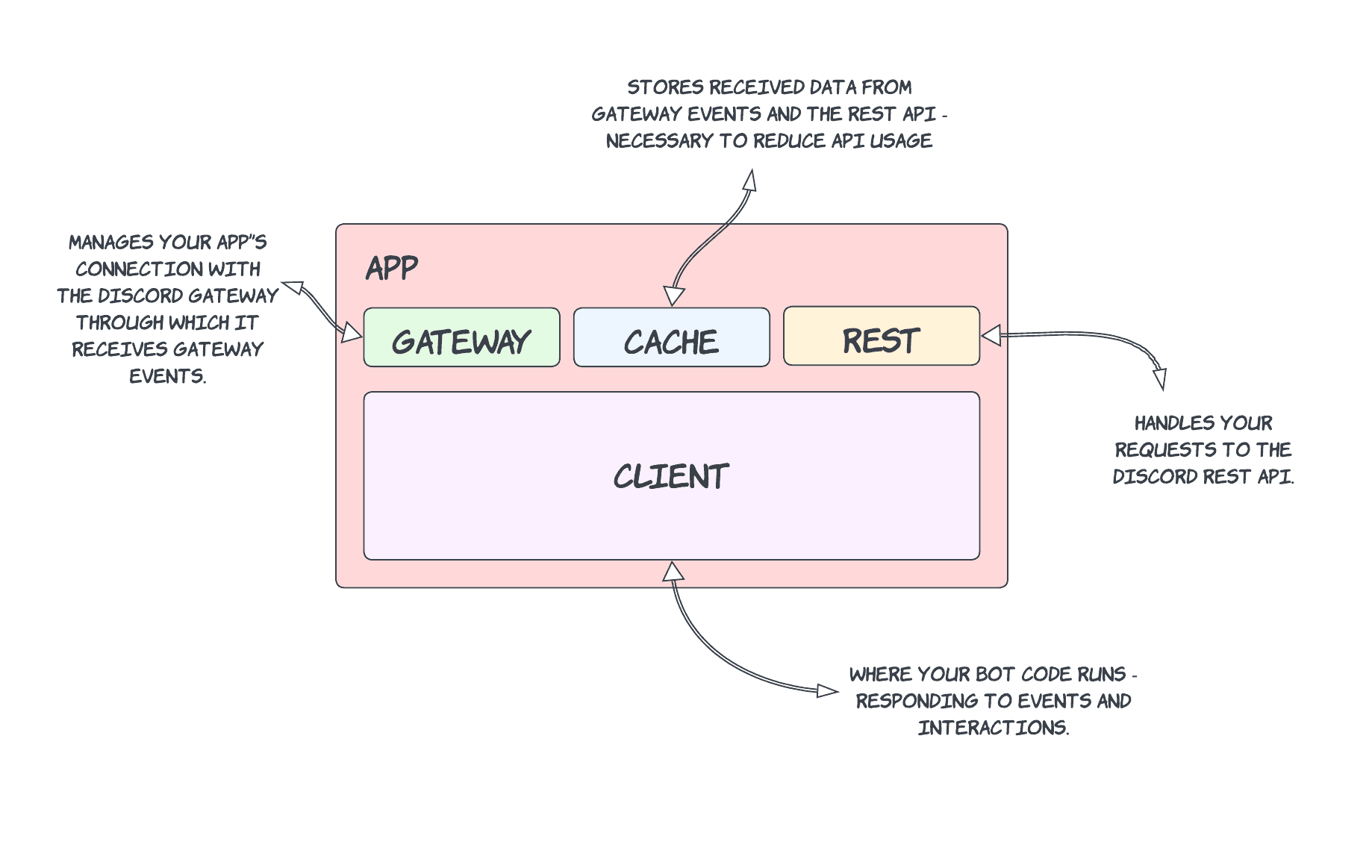
Discord Developer Introduction
Discord Gateway
The gateway is responsible for real-time communication with clients, sending events and relevant data via a websocket connection. These events are triggered by discord users, and thus are unpredictable, and can vary in volume. Because of the nature of this websocket connection, it is vital that clients maintain it, acknowledging heartbeats and resuming sessions when a RECONNECT event is received. It is also possible to send events via the gateway, such as Identify (Opcode 2), Resume (Opcode 6) & Heartbeat (Opcode 1) events.
The gateway connection uses either JSON or etf encoding - specified by the client - and can make use of zlib compression for improved efficiency. The general connection lifecycle looks like:
- Establish connection via a
GETrequest towss://gateway.discord.gg, and caching the received data, before initiating the connection. - Receive
HELLOevent (Opcode 10), which contains theheartbeat_interval. - Begin acknowledging heartbeats received by the gateway.
- Send
IDENTIFYevent, containing information about the client, as well as intents - these determine the events which the client will receive. - Receive
READYevent, and cache the data. - Handle gateway disconnects by
resumingif appropriate.
The discord gateway also mandates that bots in more than 2500 guilds must use sharding, which involves instantiating multiple connections to the gateway, helping to distribute the events across multiple connections. This can however be done at any guild count, and should be done before this threshold is met to prevent the bot from going offline.
Discord also recommends that a bot be in around 1000 guilds per shard.
Discord REST API
The REST API provides a powerful interface for getting and setting data on discord, allowing clients to fill any gaps in their cache, and make changes in guilds in response to events received via the gateway.
Ratelimits
However, the REST API also has several ratelimits. These are categorised as global or bucket ratelimits. Each response received from discord contains the following headers:
X-RateLimit-Limit: Total limit for the bucket.X-RateLimit-Remaining: Remaining requests in the bucket.X-RateLimit-Reset: UNIX Timestamp of when the bucket ratelimit will reset.X-RateLimit-Reset-After: Seconds until the bucket resets.X-RateLimit-Bucket: Ratelimit bucket ID.
These headers apply solely to bucket ratelimits, which are groups of resources on the discord API, often based on the route path, resource being accessed (guild, channel, etc), or account. If the client encounters a ratelimit on a bucket, it will also receive:
X-Ratelimit-Scope: The resource that caused the ratelimit, value can be:user,globalorshared.
However, if the client encounters a global ratelimit, it will also receive:
X-RateLimit-Global: Whether the bot encountered the global rate limit.
A bots global rate limit is 50 requests per second (3000 requests per minute).
Current Discord Libraries
The vast majority of smaller bots make use of popular libraries such as discord.js, eris and discord.py, all of which share a similar approach to managing this delicate interaction with the Discord API, where -+all components of the bot are located on the same process, on the same machine:
Advantages of Single Process Approach
- Very quick and time efficient to setup, as the bot can be run as a single app, requiring few prerequisites or other libraries.
- Hugely beginner friendly, due to the widespread adoption of this approach, and the lack of need for other technologies.
- Extremely fast, as all of the data is contained within the same process, meaning there is no need for requests to an external cache.
Disadvantages of Single Process Approach
- Data is not accessible outside of the application, as it is stored locally.
- Not scalable, because ratelimit data cannot be shared between processes, resulting in frequent rate limit errors, and risking the client being banned from the Discord API.
- If scaled across multiple processes, cached data would be duplicated - resulting in excessive data sizes.
- Lack of flexibility in the proportion of gateway instances to client instances, as these are bundled into the same process.
- Unable to hot-reload the bot in production, by incrementally updating client processes with new code, as you would be forced to bring the gateway offline simultaneously.
Alternative Approach
An alternative approach is to separate each key component of the bot into microservices, which each run independently - possibly in containers using a platform such as Docker. There would be a gateway package and a client package, which would be connected using a message broker, such as RabbitMQ or Redis (using its pub/sub mechanism).
This would allow for x number of gateway instances, and y number of client instances, which could be deployed independently of each other to adjust for demand. This would allow a bot which is in a large number of guilds, but receives few events to have a large number of gateway instances, but few client instances.
These client instances could all communicate with an independent cache, allowing data to be centralised in one location, rather than duplicated across all processes.

Advantages of Microservices Approach
- Allows for easy scaling of nodes in response to demand - e.g a sudden influx of users can be handled by simply increasing both client and gateway processes.
- Allows for disproportionate processes, for example if an app received few gateway requests, but required extensive client processing, then more client processes could be deployed than gateway processes.
- Allows for external access to data / the cache, from outside of the application. This could be useful for integrating with other applications, such as a website.
- Increased redundancy, as if a single client process becomes unavailable, this is absorbed by the other client processes. Whilst an outage on a gateway process would not have redundancy - due to discord only sending gateway events to those shards - this could be resolved by deploying two gateway processes for each set of shards, and then later filtering out duplicate events.
Disadvantages of Microservices Approach
- There is significantly more overhead, with a need for a containerisation platform - e.g Docker.
- Larger learning curve, as this is not as easily implemented as a library such as Discord.js
Conclusion
A microservice architecture provides a new and interesting way to handle chatbots - in this post, this has focussed on the Discord platform, however these concepts are applicable to other services which also have comprehensive and detailed API's. I addressed this need for a microservice architecture by developing my own library - Fawkes.js - which provides easy to use and flexible packages that can be deployed in containers.